クローラーとは?SEOにおける重要性や対策方法を徹底解説!
投稿日:2023/02/28 (更新日:)

「クローラー」とは、ウェブ上のデータを取得するために巡回しているロボットを指します。
クローラーに発見してもらい、必要なデータをAIが判断し、検索結果に反映させる重要な役割を担っています。
このことから、サイトのページをインデックスさせるにはクローラーが巡回しやすいサイト設計や対策が必要です。
そこで本記事では、そもそもクローラーとは?SEOにおける重要性やクローラーが巡回しやすくする対策方法を詳しく解説します。
クローラーとは?

クローラーとは、インターネット上に存在するWebサイトや画像、動画などの情報を取得するために巡回しているロボットプログラムのことを指します。
ロボットが自動的に検索データベースを作成し、ページの検索順位を決める重要な役割を担っています。
Web上を這いまわる(クロールする:crawling)ことから「クローラー」と呼ばれます。
Google、Yahoo!、Bingといった検索サイトを提供する企業のほとんどが「ロボット型検索エンジン」をシステムに組み込んでいます。
当初は手動でページをカテゴリー分けする「ディレクトリ型検索エンジン」を採用しておりましたが、
現在は「ロボット型検索エンジン」が主流となっており、クローラーが自動でインターネット上に公開されている情報を収集し、キーワードごとにデータベース化します。
収集されたデータベースを元に、検索ユーザーのニーズに合う結果を画面に並べることができます。
このことから、クローラーは検索エンジンの仕組みやSEOを理解するうえでとても重要です。
クローラーの種類を紹介
クローラーは1種類だけではありません。代表的なクローラーを紹介します。
- Googlebot (Google)
- Yahoo Slurp (Yahoo!)
- Bingbot (Microsoft)
- YandexBot (Yandexロシア)
- Baiduspider (Baiduspider中国)
- Yetibot (Naver韓国)
この中でもGoogleは国内で7割以上と圧倒的に高いシェアを誇っています。このことから、Googlebotに合わせた対策を講じることがSEO対策では重要です。
また、Googleのクローラーは1種類ではなく、PC用やスマホ用、画像用、動画用などデータごとに細分化しクローリングしています。
- 「Googlebot」メインのクローラー
- 「Googlebot-Image」画像用
- 「Googlebot-Video」動画用
このように、さまざまなクローラーのロボットが昼夜問わず巡回し、Webサイトのデータを収集しています。
クローラビリティとは?
クローラビリティとはクローラーがWebサイトを巡回しやすくするように最適化することです。
クローラビリティを改善することでクローラーがページを発見しやすくなるため、クローラビリティの改善はSEO対策で重要になります。
詳しい対策法を後ほど詳しく解説します。
クローラーの対象ファイル
クローラーの巡回で収集するファイルを紹介します。
- テキストファイル
- HTMLファイル
- CSSファイル
- 画像ファイル
- 動画ファイル
- PDFファイル
- JavaScriptファイル
- FLASHファイル
- JSONファイル
- 音声ファイル
- シンジケーション
私たちがブラウザ上で閲覧している情報と同じものをクローラーは収集しています。
Googleクローラーの仕組みとクローリングの流れを解説

先ほど説明した通り、クローラーは「ロボット型検索エンジン」がWebサイトを巡回することです。
クローラーの巡回の仕組みと、クローリングの流れについて詳しく解説します。
ロボット型検索エンジンは、大きく分けて5つの流れでクロールしインデックスされます。
- クロールキュー
- クローリングとパーシング
- インデックス
- ランキング
1.クロールキュー
クロールには準備段階として、クロール対象のURLを「クロールキュー」に追加します。
XMLサイトマップや、過去のクロールによって得られたURLを「クロール待ちURLリスト」に追加します。
Googlebotはクロールキューから優先度が高いURLを取得し、クロールが巡回に訪れます。
2.クローリングとパーシング
クローラーがWebサイトを発見すると、最初に「クローリング」を開始します。
ロボット型検索エンジンにおいて、プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、Webページ上の情報を複製・保存することを「クローリング(crawling)」と呼びます。
リンクからリンクへとサイト内を巡回し、Webサイト上の無数にあるページ情報を収集します。
データの収集が終わるとクローリングで得た情報を元に、ページの解析に移ります。その作業をパーシングと呼びます。
3.インデックス
ページの解析を終えると、検索エンジンのデータベースへ「登録」する作業へ移ります。
登録が行われ、検索結果に表示されるようになることを「インデックス」と呼びます。
クローラーに巡回されるだけでは、検索結果には表示されません。インデックスされて初めて、検索結果に表示されるようになります。
4.ランキング
インデックスされたページは、Google検索アルゴリズム(ランキング要因)に沿ったデータで評価され、検索クエリ(検索窓に入力するキーワード)によってページがランク付けされます。
この検索順位(ランキング)はGoogleが設定している200以上の要素から構成される「アルゴリズム」によって決定します。
SEOにおけるクローラーの重要性を解説

検索結果はクローラーが収集した情報をもとに形成されることは先述でも述べましたが、SEOにおいてクローラーは重要な役割があります。
クローラーが情報収集しないとインデックスされないため、検索結果に表示されません。
つまり、良質なコンテンツを掲載しても、ユーザーに閲覧してもらえないことになります。
検索エンジンは、検索するユーザーのニーズに合った有益な情報を正しく提供するために、データベースが構築されています。
クローラーは1度のクローリングで巡回できる上限があり、クローラーは一度訪れたら終わりではなく、定期的に巡回に訪れます。
常にサイト内に最新情報が更新されていたり、価値のある情報が正しく掲載されている有益なサイトは、クローラーが訪れる頻度も高まります。結果として、サイト内の全体の順位が高くなる可能性があります。
このことから、自身のwebサイトがSEOで高い評価を得るためには、まず第一にクローラーに作成したWebサイトを発見してもらうことが重要です。
インデックスを確認する2つの方法

インデックスがされているかを確認する方法を2つ紹介します。
- Googleサーチコンソールで確認する
- 「site:」検索で確認する
①Googleサーチコンソールで確認する
Googleサーチコンソールを使い、ページがインデックスされているかどうか確認する方法です。
手順1:Search Console画面上部の検索窓に確認したいURLを入力
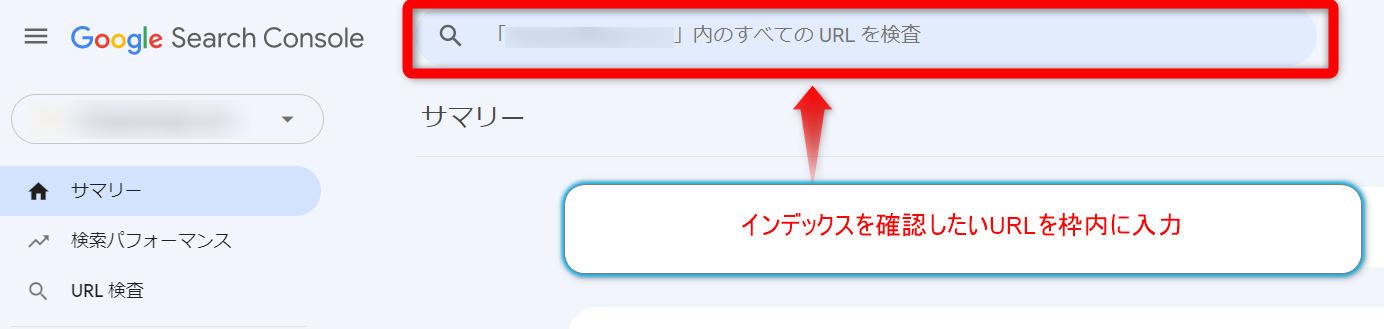
サーチコンソールの「URL検査」窓にインデックスを確認したいURLを入力もしくは、ペーストし検査を実行します。
手順2:インデックスを確認する
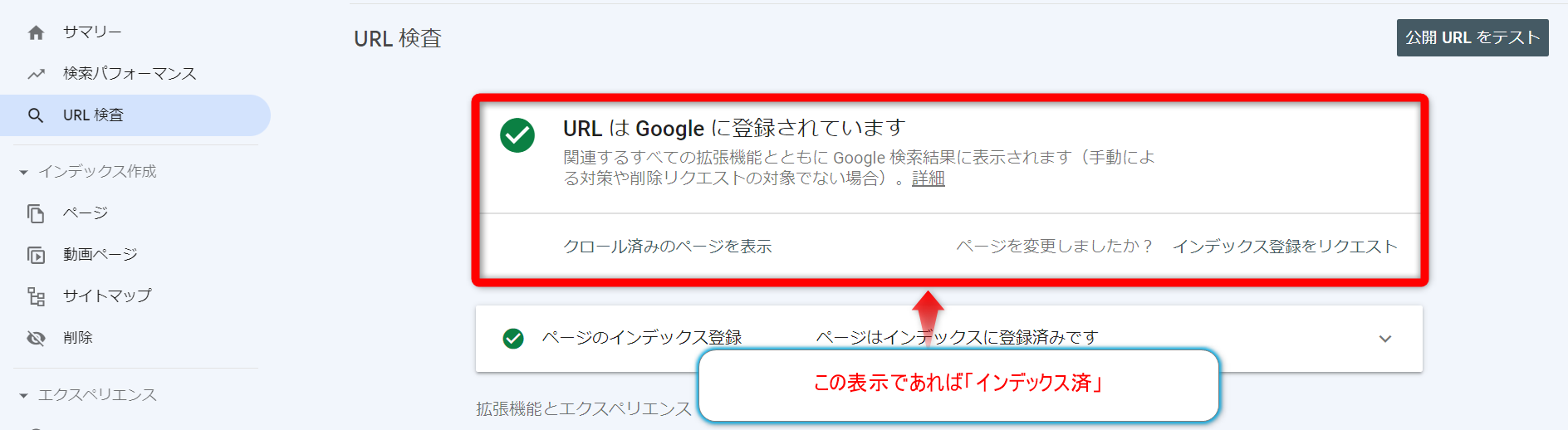
URL検査後に結果が表示されます。画像のように「URLはGoogleに登録されています」と緑のチェックで表示されればインデックス登録がされていることになります。
しかし、検査したURLが「URLはGoogleに登録されていません」と表示されて場合、インデックスされていないことを示しています。
この場合は、「インデックス登録をリクエスト」ボタンを押し、送信しましょう。
②「site:」検索で確認する

インデックスを確認したいURLの前に「site:」を加えて検索します。
例:site:https://example.com/○○
このように入力し検索するとインデックスされているかを確認できます。
インデックスされている場合は、検索結果として表示されますが、インデックスされていない場合は表示されません。
インデックスがされていない場合は、クローラーが巡回に訪れていない可能性があります。
巡回を促す施策を講じましょう。
SEO対策に重要であるクローラーの巡回を促す10の方法を徹底解説

クローラーは全てのウェブサイトに満遍なく巡回しているわけではありません。また、公開したページがすぐにクローリングされるとも限りません。
そのため、SEO対策をするうえでは、クローラーができる限りサイト内を巡回しやすくするための対策が重要になります。
このようなクローラーの巡回のしやすさを示す指標のことを「クローラビリティ」と呼びます。
SEO対策に重要であるクローラーの巡回を促す方法を10通りに分けて、わかりやすく解説します。
1.XMLサイトマップを設置する
XMLサイトマップとは、作成したサイトの構成やコンテンツをクローラーに正しく理解してもらうためのファイルです。
サイトマップには、サイト内にあるページのURLの一覧が記載されています。
クローラーは、この一覧を参考にしてサイト内の巡回を行うため、サイトマップを作成することで、クローラーがサイト内を効率良く巡回できるようになり、インデックスが促進されます。
一般的には、「sitemap.xml」と命名したファイルをサイトのトップディレクトリにアップロードします。
詳しい設置方法や手順は以下の「XMLサイトマップの設置方法を詳しく解説」を参考にしてください。

2.インデックス登録をリクエスト
Google検索エンジンでは、クロールを促すリクエストを送信できます。
新規で作成したページやページを大幅に更新した場合は、GoogleサーチコンソールのURL検査を活用して、Googleにクロールを促します。
クロールのリクエスト方法
リクエスト方法は簡単で、以下の通りです。
①サーチコンソールの枠内にリクエスト送信したいURLを入力。
②「インデックス登録をリクエスト」をクリックする。
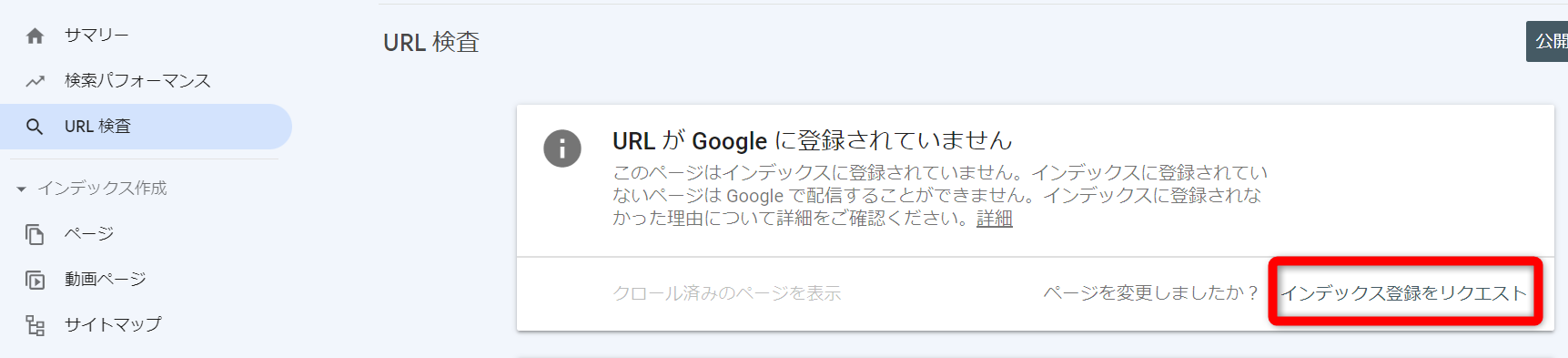
この2つの工程だけでクローラーへのリクエストは完了します。
正し、リクエストを出したからと言って、必ずインデックスされるわけではありません。
3.URLを統一する
同じページでも複数のURLでアクセスできるケースがあります。
例えば、「http」と「https」や「wwwあり」と「wwwなし」少しの違いでも同じページにアクセスできます。
クローラーに、同じ情報を持つ別ページを巡回することなり、クローラーにとっては無駄な動きです。
この動きを「クロールバジェットの浪費」と呼びます。
クローラーには1度にクロールできる上限が決まっているため、無駄な巡回をさせるのはもったいないことです。
URLを統一することで、無駄なクローリングを回避し、クローラーが巡回しやすい環境を整えられます。
また、同じ情報をもつURLは、重複コンテンツと判断される可能性があります。重複コンテンツは、Googleのペナルティの対象になるリスクがあるので、注意が必要です。
重複コンテンツでペナルティを受けた場合、放置しておくと検索順位を下げる要因になります。
このようなリスクを避けるためにもURLを統一するようにしましょう。
重複コンテンツについては、こちらの記事で詳しくご紹介しています。

301リダイレクトで統一させる
301リダイレクトは検索エンジンやブラウザに対して、URLを転送されたことを指します。
例えば、「https://www.example.com」「https://example.com」のように2つのURLが存在するとします。
このような場合、「https://www.example.com」に301リダイレクト処理をすると、「https://example.com」へと転送され、URLを統一できます。
このように統一することにより、クローラーは1つのURLに転送されるため、無駄なクロールを防ぐことができます。
301リダイレクト以外にも、「canonicalタグ」の設置でURLを統一させる方法があります。
canonicalタグは、「正規のURL」を検索エンジンに認識させるためのタグです。
しかし、レンタルサーバーの設定などの環境要因で、301リダイレクトができない場合以外は、canonicalタグを使用せず、301リダイレクトで対応しましょう。
4.robots.txtを設置する
robots.txt(ロボッツ・テキスト)とは、特定ページへのクローラー巡回を禁止または制御するファイルです。
robots.txtファイルにクローラーの巡回をブロックする設定をし、サイトにファイルをアップロードすることで、無駄なクローリングを減らし、クローラーをコントロールできるようになります。
重要ではないページのクロールをrobots.txtファイルで制御し、重要なページに適切なクローリングができます。クロールを最適化することで、SEOに良い影響をもたらします。
特に大規模サイトになりつつある場合は、robots.txtを設定し、クローラーが巡回しやすいサイト環境にしましょう。
5.リンク切れしているページを整理する
URLを変更したり、ページの削除などが要因で、元々あったURLにアクセスできない状態を「リンク切れ」と言います。
リンク切れページが存在していると、「クローラビリティの低下」や「ユーザビリティの低下」懸念されるため注意しましょう。
ページのリンクは「404エラー」と表示され、リンク切れとなっていることがわかります。
クローラーにとって、クローリングできないページが存在することは、クローラビリティがよい状態ではありません。
また、リンク先のページがリンク切れで閲覧できない状態は、検索ユーザーにストレスを与えることになり、ユーザビリティの低下を招きます。
サイトのページ数が多くなれば、それに伴い内部リンクが多くなるので、リンク切れを起こす可能性も増えます。意識して、サイト内を整理しリンク切れを防ぎましょう。
6.内部リンクを最適化する
クローラーの仕組みでも説明したように、クローラーはリンクからリンクを辿ってサイト内を巡回する仕組みになっています。
このことから、内部リンクを設置することにより、クローラーがページからページへと巡回しやすくなります。
関連性の高いコンテンツをリンクで繋ぐことにより、サイトの網羅性を高める効果があり、SEOにおいても重要な施策です。
一方で、関連性のない内部リンクを多く貼ることは逆効果になる恐れがあるため、適切な内部リンクの設置を心がけましょう。
また、Googleの検索エンジンはhref 属性が指定された「a (アンカー)タグ」しかクロールできないため、必ずHTMLの「a (アンカー)タグ」を用いたリンクを設置しましょう。
設置例:<a href="リンク先URL"> リンク先へ </a>
Wordpressであれば、「Ctrl + K」のショートカットキーでも設置が可能です。
7.パンくずリストを設定する
パンくずリストとは、閲覧中のページがサイト内のどの位置にあるかを階層構造で示したリンク付きのリストのことです。

それぞれのリストにはリンクが貼られており、クリックすると上位階層に戻る機能です。
クローラーはリンクを辿って移動するため、パンくずリストを設置することでクローラーが巡回しやすい環境を作れます。
また、パンくずリストは検索ユーザーにとっても、視覚的に階層を理解してもらいやすく、関連カテゴリーへのサイト内の回遊率の向上も見込めます。
パンくずリストの設定は、こちらの記事で詳しく解説しています。

8.ページの表示速度を改善する
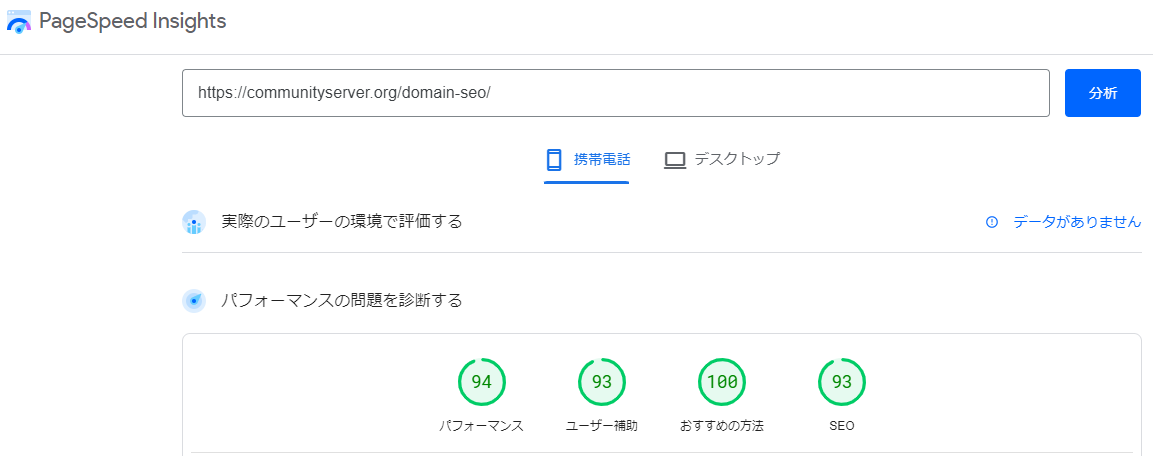
Googleが提供する「PageSpeed Insights」でサイトスピードを計測出来ます。
ページの表示速度が高まるとユーザーの利便性が向上するだけではなく、クローラーのクロール速度も上がります。
また、サイトの読み込みスピードが遅い場合は、ユーザーの離脱につながります。離脱率が高いと、SEOにも悪影響があるため、ページの表示速度の改善を図りましょう。
9.サイト構造の階層を深くしすぎない
サイト内の階層が深いとクローラーがページ発見までに時間がかかります。
サイトの階層は、トップページから1~2クリックで全てのページに到達できる構造が理想的です。
ただし、階層が浅いことがSEO評価に直接影響するわけではありませんが、ディレクトリ階層が浅い方がクローラーは巡回しやすくなります。
もし、どうしてもディレクトリ構造が深くなるサイトを運用する場合は、サイトマップや階層が浅くなるように内部リンクを適切に設置しましょう。
10.Javascriptを最適化する
「JavaScript」とは、動的なWebページを作成する事のできるプログラミング言語です。
Googlebotはすべてのページをデータの視覚的変更(レンダリング)するためキューに入れます。
Googlebot はレンダリングされた HTML のリンクを再度解析し、見つかった URL をクロールするためキューに入れます。
また、Google はレンダリングされた HTML を使用してページをインデックスに登録します。
Googleのリソースに空きができると、レンダリングしてJavaScriptを実行する流れとなっています。
レンダリング時にJavaScriptの実行に時間がかかると、レンダリングが行われず、インデックスされない場合もあります。
以前よりも、GoogleクローラーのJavaScript処理能力は良くなっており、大半の場合はインデックスされます。
しかし、JavaScriptによるインデックスへの悪影響の可能性はまだ高くあり、JavaScriptの最適化は重要です。
まとめ
Google検索におけるクロールの仕組みや確認方法、クロールの最適化などを解説しました。
ユーザーニーズを満たした価値の高いページを作成し、クロールの仕組みを理解してクローラビリティの向上を図ることは、SEOの基本です。
クローラーの仕組みを理解することで、インデックスを早める効果が期待できるだけでなく、クローラーが巡回しやすいサイト構造はSEOにおいてもとても重要だと理解できたのではないでしょうか。
クローラビリティの向上は、インデックスや検索順位にダイレクトに影響を及ぼすため、非常に重要な対策です。
作成したコンテンツがいつまでたっても検索結果に表示されない場合は、クローラビリティに問題があるかもしれません。
そのような場合は、この記事でご紹介したクローラーの巡回を促すための施策を実行しましょう。