BERTとは?Googleが導入した自然言語処理(NLP)を解説
投稿日:2021/12/22 (更新日:)

BERTという自然言語処理(NLP)技術が、2019年10月25日にGoogleの検索アルゴリズムに導入されました。
通称「BERTアップデート」により、SEOや検索順位にどのような影響があるか気になる人も多いはずです。
そこで今回は、
- そもそもBERTとはどんな技術なのか
- GoogleがBERTを検索アルゴリズムに導入した理由
- BERTがSEOや検索順位に与える影響
- BERTの仕組みや特徴
- BERTを最適化させる方法
以上について、くわしく解説していきます。
BERTアップデートの理解を深めて、検索ユーザーにとってより利便性の高いコンテンツを提供できるようになりましょう。
BERTとは
BERT(バート)とは「Bidirectional Encoder Representations from Transformers」の略で、「トランスフォーマーからの双方向エンコーダー表現」という意味のGoogleが開発した自然言語処理(NLP)技術です。
かんたんに説明すると、BERTは複雑または長い文章を双方向(文頭や文末、単語の前後など)から読み取ることで文脈を正確に読み取れる技術をいいます。
BERTは、従来の自然言語処理(NLP)とは異なる検索アルゴリズムを持っており、さまざまな検索クエリに対して正確に検索結果を出力することが可能です。
ですので、Google検索においてBERT導入後は、よりユーザーの検索意図に近い検索結果を表示できるようになりました。
ここで「そもそも自然言語処理(NLP)とはどのような技術なのか」や、「なぜGoogleがBERTを検索アルゴリズムに導入したのか」について疑問が生じている人も多いはずです。
これらの疑問について、くわしく説明していきます。
自然言語処理とは
自然言語処理とは、人間が普段使用している言語(自然言語)をコンピュータや機械に理解させることです。
自然言語処理は英語で「Natural Language Processing」と表され「NLP」と略されます。
自然言語処理(NLP)技術の目標は、私たちが日ごろからコミュニケーションとして使用する言語のあいまいな要素も理解できるようになることです。
自然言語処理(NLP)技術のなかでも、BERTはGoogleが開発した技術であるためWeb業界でとくに注目されています。
BERTは、その他の自然言語処理(NLP)よりも「文脈に隠れているあいまいな要素」を理解できることが最大の魅力です。
GoogleがBERTを検索アルゴリズムに導入した理由
GoogleがBERTを検索アルゴリズムに導入した理由は、これまで以上に検索ユーザーの意図を理解したいから(※)です。
Googleが今までよりも検索ユーザーの意図を理解したいのは「検索クエリの多様化」と「音声検索の発達」が背景にあります。
パソコンから行うのが主流であった「検索」が、スマートフォンの普及により身近になったことが「検索クエリの多様化」の要因です。
そして、スマートフォンやスマートスピーカーに搭載されているAIアシスタントの進化とともに「音声検索の発達」が進行しました。
そのため近年では、スマートフォンや音声検索の普及により、検索キーワードがより話し言葉に近い口語的なものになってきているのです。
そうした背景から、GoogleはBERTという人間の言語をコンピュータに学習させるための技術を導入したのです。
※参考:Understanding searches better than ever before
BERTがSEOに与える影響
BERTがSEOに与える影響は大きいといえます。
BERTがSEOに与える影響について、以下の3つから解説していきます。
- Googleの公式アナウンス情報
- 実際のGoogle検索での順位変動
- 予想される検索結果への影響
Google公式アナウンス
Googleは2019年10月25日にBERTアップデートについて以下の公式アナウンスを出しています。
Meet BERT, a new way for Google Search to better understand language and improve our search results. It's now being used in the US in English, helping with one out of every 10 searches. It will come to more counties and languages in the future. pic.twitter.com/RJ4PtC16zj
— Google SearchLiaison (@searchliaison) October 25, 2019
Google検索で言語をよりよく理解し、検索結果を改善するための新しい方法であるBERTをご覧ください。現在、米国では英語で使用されており、検索の10回に1回の割合で使用されています。将来的には、より多くの郡や言語に対応する予定です。
※ツイートを翻訳
上記のツイートでは、BERTアップデートにより「クエリの10分の1」の検索ランキングへの影響があると述べています。
そして、2019年12月10日の以下のアナウンスでは、英語検索以外にも日本語を含む世界の70以上の言語に対応したことを発表しました。
BERT, our new way for Google Search to better understand language, is now rolling out to over 70 languages worldwide. It initially launched in Oct. for US English. You can read more about BERT below & a full list of languages is in this thread.... https://t.co/NuKVdg6HYM
— Google SearchLiaison (@searchliaison) December 9, 2019
Google検索で言語をよりよく理解するための新しい方法であるBERTは、現在、世界中で70を超える言語に展開されています。 最初は10月にアメリカ英語で発売されました。 以下でBERTの詳細を読むことができ、言語の完全なリストはこのスレッドにあります。
※ツイートを翻訳
実際にBERTアップデートによる日本語検索の検索結果に影響を受けている一例について、Googleが述べています。
それが『2019年のブラジルから米国への旅行者はビザが必要です。』というクエリの検索結果です。
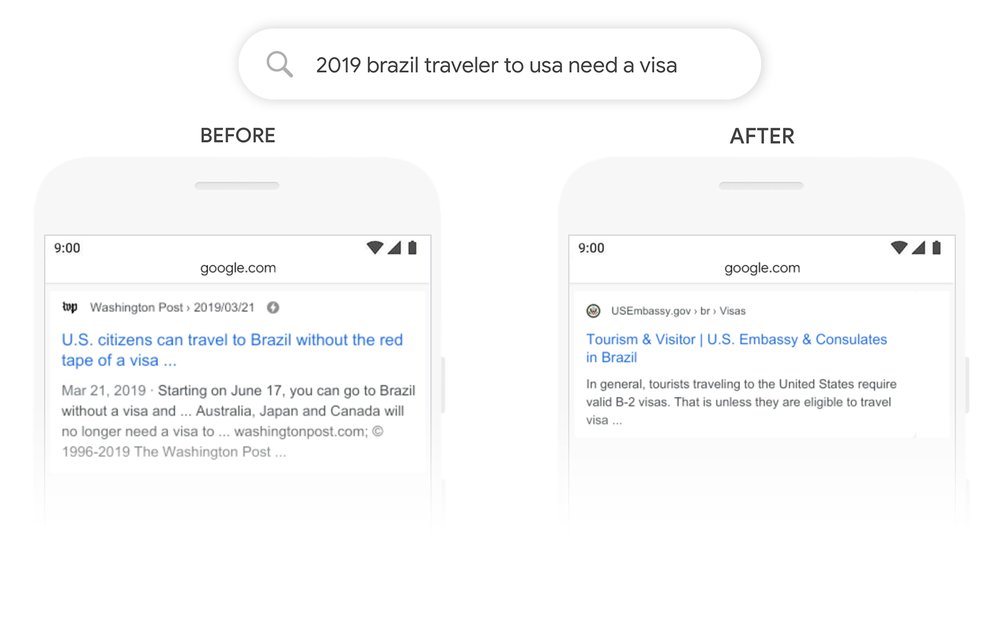
引用元:https://www.blog.google/products/search/search-language-understanding-bert/
BERTアップデート以前は、上記クエリをGoogle検索すると「ブラジルに旅行する米国市民に関する内容」が検索結果に表示されました。
この検索結果は、Google検索が複雑または長い文章を理解できないことが原因です。
一方で、BERTアップデート以降に上記クエリをGoogle検索すると、検索ユーザーの意図に沿った検索結果が表示されるようになりました。
これは、BERTの導入により「to」という英単語の意味を口語的な文脈から理解できるようになったためです。
このように、BERTは従来の自然言語処理(NLP)技術では処理できない言葉のニュアンスや意味を文脈より正確に理解できます。
その結果、検索ユーザーを満足させられる検索結果を表示できるようになるのです。
Google検索の順位変動の状況
BERTアップデートによるGoogle検索の順位変動は、過去に実装された大型アップデートと比較すると小さいといえます。
その理由は、BERT導入により検索結果が適正化される対象が複雑または長い文章(ロングテールキーワード)であるためです。
しかしBERT導入により、複雑または長い文章(ロングテールキーワード)での検索が増加するため、新たな検索クエリで自身のページが認知される可能性があります。
BERT導入により認知されるページがある一方で、検索順位が下がり認知されなくなるページも同数で存在するのです。
BERT導入でご自身のページへのトラフィックを増加させるためには、口語的な検索クエリについても分析する必要があります。
BERTが検索結果に与える影響と予想されること
GoogleのBERT導入は、自然言語処理(NLP)の技術的アップデートに過ぎません。
今後は複雑または長文な文脈を理解する技術がさらに進化し、スマートスピーカーやチャットボットの進歩と普及が予想されます。
そうなると、一般的な検索クエリに加えて日常的な会話型の複雑なクエリが増えてくるはずです。
会話型の複雑なクエリは一般的な検索クエリに比べると検索ボリュームは多くありません。
ですので、会話型の複雑なクエリに備えて優先的に対策する必要はないように思えます。
しかし、検索ユーザーがスマートスピーカーやチャットボットなど、口語的なクエリで検索を行う場面こそ「より早く正確な情報を届けられるか」が重要となります。
このように、検索ユーザーが「早急に知りたい」などの急いでいる場面で、検索クエリに対する正確な回答ができるページがあればとても重宝されるはずです。
さらに、会話型の複雑なクエリを「強調スニペット」や「リッチリザルト」など、視覚的要素を含ませて返答できれば、より多くのユーザーの役に立つでしょう。


BERTの仕組み
BERTは事前学習モデルであり、はじめに大量のラベルが付いていないデータをトランスフォーマーが処理することで学習する仕組み(※)です。
その後、処理されたデータに少量のラベルが付いているデータを使用して微調整(ファインチューニング)します。
BERTの仕組みの利点は、従来の自然言語処理(NLP)よりも事前に大量のラベル付きデータを準備する必要がなくなること、そしてより口語的な文章の解釈に優れていることです。
また、事前学習で文章を双方向(文頭や文末、単語の前後など)から読み取ることで文脈の理解が深まります。
具体的には「Masked Language Model」と「Next Sentence Prediction」の2つの手法を同時進行で行い学習します。
「Masked Language Model」と「Next Sentence Prediction」の2つの手法について解説していきます。
※参考:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
1.Masked Language Model
「Masked Language Model」は、文章を双方向のトランスファーにより学習するための自然言語処理(NLP)モデルです。
文章を文頭や文末、単語の前後などから読み取ることで目的の単語を理解します。
そして、従来の自然言語処理(NLP)モデルよりも言語処理精度が高いのが特徴です。
一方、従来の自然言語処理(NLP)モデルは、文章を一方向からしか処理できません。
そのため、目的の単語を理解するのに前の文章データから予測する必要があります。
Masked Language Modelの具体的な処理パターンは、以下の通りです。
- 【パターン1】入力された文章の15%の内、80%の単語をMASKする(隠す)
- 【パターン2】入力された文章の15%の内、10%の単語をランダムな単語に置き換える
- 【パターン3】入力された文章の15%の内、10%の単語はそのまま処理する
上記のパターンのように文章の単語を処理して、文脈全体を学習します。
2.Next Sentence Prediction
「Next Sentence Prediction」は、入力される2つの文章の関係性を学習するための自然言語処理(NLP)モデルです。
前述したMasked Language Modelは、ある単語に関する学習は可能ですが、文章ごとの学習はできません。
BERTの自然言語処理(NLP)モデルは、2つの文章が隣り合うものなのかを判断できるNext Sentence Predictionにより実現しています。
Next Sentence Predictionは、入力された文章の片方を50%の確率で他の文章に置き換えて、2つの文章が隣り合うものかを判断します。
3.転移学習(Fine-Tuning)
BERTは、Masked Language ModelとNext Sentence Predictionの2つの手法の他にも「転移学習(Fine-Tuning)」を導入し、自然言語処理(NLP)の精度を向上させています。
転移学習とは、ある領域の知識を別の領域の学習に適用させる技術です。
BERTの3つの特徴
BERTの3つの特徴は以下の通りです。
- 言語処理の精度が高い
- 汎用性が高い
- 性能の数値評価(ベンチマーク)が高い
それぞれの特徴を解説していきます。
言語処理の精度が高い
ここまでも何度も説明してきましたが、BERTは従来の自然言語処理(NLP)技術よりも言語処理制度が高いことが特徴の一つです。
従来の自然言語処理(NLP)技術では「to」「for」などの前後の文脈により意味が大きくかわる単語の意味を正確に理解できませんでした。
これが検索クエリによって、ユーザーを満足させる検索結果が表示されない原因です。
しかしBERTアップデート後は、文脈や検索意図を正確に理解し、ユーザーの検索意図により近い検索結果を表示できるようになりました。
特に、複雑また長文の文脈理解の改善が見られ、今後はスマートスピーカーなど音声検索のさらなる進化と普及につながるでしょう。
汎用性が高い
BERTは、さまざまなタスクに対応可能な汎用性が高いことが特徴の一つです。
従来の自然言語処理(NLP)技術は、特定のタスクにのみ対応しています。
しかし、BERTは構造を修正することなく、さまざまなタスクに応用可能で、既存のタスクに転移学習(Fine-Tuning)させることで、自然言語処理の精度を向上させられるのです。
性能の数値評価(ベンチマーク)が高い
BERTは、GLUE(The General Language Understanding Evaluation)という性能の数値評価(ベンチマーク)が高いことが特徴の一つです。
GLUEには、文類似度や推論などの8つのタスクのデータセットが含まれます。
| データセット | タイプ | 概要 |
|---|---|---|
| MNLI | 推論 | 前提文と仮説文が含意・矛盾・中立のいずれの関係か判断するタスク |
| QQP | 類似 | 2つの質問内容の意味が同じかどうかを判断するタスク |
| QNLI | 推論 | 文と質問が与えられ、文に答えが含まれるかどうかを判断するタスク |
| SST-2 | 1文分類 | 文に対する感情分析(ネガティブ・ポジティブ)タスク |
| CoLA | 文が文法的に正しいかどうかを判断するタスク | |
| STS-B | 類似判定 | 2文の意味の類似スコア(1~5段階)を判断するタスク |
| MRPC | 2文の意味が同じかどうかを判断するタスク | |
| RTE | 2文の含意関係を判断するタスク |
これらにより、自然言語処理(NLP)技術の総合的な性能の数値評価(ベンチマーク)が算出されたところ、BERTが最高性能であることが証明(※)されました。
※参考:https://aclanthology.org/W19-5006/
性能の数値評価(ベンチマーク)の高さゆえに、今後BERTは生体医療分野など、さまざまな分野で活用されることが期待されている自然言語処理(NLP)技術なのです。
BERTを最適化させる方法
BERTを最適化する方法は特にありません。
強いていうなら「今まで以上にユーザーの検索意図に沿ったコンテンツを用意する」ことです。
それでは、くわしく見ていきましょう。
ユーザーの検索意図に沿ったコンテンツを用意する
BERTの導入により、ユーザーの検索意図により近い検索結果が表示されるようになります。
ですので、今までよりも検索クエリやキーワードの意図を理解しなければ、検索結果に表示されません。
また、さまざまな口語的な検索クエリからのトラフィックも期待できるので、検索ユーザーの観点でコンテンツ制作をしましょう。
コンテンツのわかりやすさと伝わりやすさを重視する
GoogleのBERTアルゴリズムに評価されるためには、コンテンツのわかりやすさと伝わりやすさを重視しましょう。
BERTの導入により、Googleは複雑または長文でも文脈を理解できるようになりました。
しかし、はじめから簡潔に認識されやすい文章内容にしておけば、検索クエリの意図との関連性がクローラーに伝わりやすくなるはずです。
誤字脱字はもちろんのこと、コンテンツを校閲して、わかりやすさと伝わりやすさを追求してみてください。
オリジナルコンテンツを提供する
独自性のあるオリジナルコンテンツを提供することは、BERTアルゴリズムに評価されるためにとても大切です。
コピーコンテンツは、Googleでペナルティの対象となることは多くの人が理解しているはずです。
しかし、未だに他のページの単語を類義語に置き換え、そのままリリースしているコンテンツが多く見られます。
BERTにより、今までよりも文脈を理解できるようになったことで、コピーコンテンツへの対応が強化されるはずです。
また、知らないうちに類似コンテンツとしてコピーコンテンツにならないためにも、競合サイトを十分に調査してペナルティとならないようにしましょう。
BERTを導入してユーザーの意図に沿った検索結果を出力させよう
今回は、Googleが開発した自然言語処理(NLP)技術の「BERT(バート)」について、くわしく解説しました。
BERTアップデートは、ユーザーの検索意図を正確に理解して検索結果を表示できるようになるため、これまで以上に「ユーザーファースト」でコンテンツを作成する必要性が高まりました。
話題になるほどの大きな変化は感じられない人も多いですが、強調スニペットの生成にBERTが関係しているなど、実は身近な検索結果に影響を及ぼしているのです。
BERTの理解を深めて、ユーザーの意図に沿った検索結果を出力させましょう。